A Suite of Linguistic Tools for Use with the Penn-II Treebank
Abstract
Proceedings of LFG03; CSLI Publications On-line
Treebanks of parsed, annotated text corpora are becoming more and more
important resources in many areas of descriptive, theoretical and
computational linguistic research. In LFG too, there exists quite a
large body of work on semi-automatic extraction of large-scale
resources, including grammars (e.g. Cahill et al., 2002a;
Zinsemeister et al., 2002; Frank et al., 2003),
subcategorisation frames (van Genabith et al., 1999; Cahill
et al., 2003), and < c,f > pairs of LFG
representations (e.g. Cahill et al., 2002b).
The current paper describes a suite of tools for inspection of the
Penn-II Treebank. Cahill et al. (2002a) describes an algorithm
for automatically annotating the 1 million words in 50,000 sentences
in the treebank with f-structure annotations. This annotation method
scales up by an order of magnitude on the method of van Genabith
et al. (1999). Given the size of the dataset, a number of tools
have been built in order to facilitate the inspection and annotation
of the treebank trees. The tools include:
- treebank inspection and viewing options which enable searching
for CFG-rule tokens extracted from the treebank;
- graphical display of trees and subtrees according to rule instances;
- display of the yield of the subtree (with and without context);
- tagging and PCFG-parsing of new input;
- an automatic annotation tool;
- an f-structure generator.
Figure 1 illustrates the display of a < c,f >
pair for the simple sentence A man saw a woman. While some of
the tools have been described in (Cahill and van Genabith, 2002), we
shall demonstrate a number of new facilities, including the extraction
of subcategorisation frames and quasi-logical forms, an automatic
annotation algorithm, and full LFG parsing into both c- and
f-structures of unseen input, should the user require. (Available at
http://www.computing.dcu.ie/~acahill/get_lfg.html) This is made
possible by a PCFG chart parser (based on the CYK algorithm) which
operates on CFG grammars extracted by the annotation algorithm
presented in Cahill et al. (2002a).
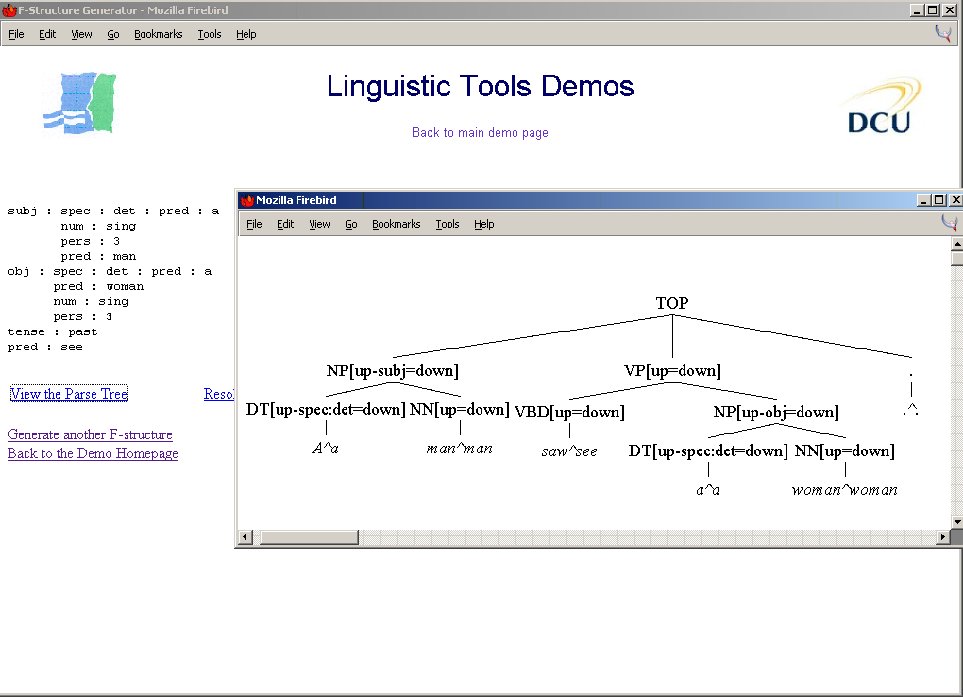
Figure 1: A $< c,f >$ pair for a simple sentence
References
- Cahill, A., M. McCarthy, J. van Genabith and A. Way (2002a): `Automatic
Annotation of the Penn-Treebank with LFG F-Structure Information', in
Proceedings of the LREC Workshop on Linguistic Knowledge
Acquisition and Representation: Bootstrapping Annotated Language
Data, Las Palmas, Spain, pp.8-15.
- Cahill, A., M. McCarthy, J. van Genabith and A. Way (2002b): `Parsing
Text with a PCFG derived from Penn-II with an Automatic F-Structure
Annotation Procedure', in M. Butt and T. Holloway-King (eds.)
Proceedings of the Seventh International Conference on LFG, CSLI
Publications, Stanford, CA., pp.76-95.
- Cahill, A., M. McCarthy, J. van Genabith and A. Way (2003):
`Quasi-logical forms from f-structures for the Penn treebank', in
Proceedings of the Fifth International Workshop on Computational
Semantics, Tilburg, The Netherlands, pp.55-71.
- Cahill, A. and J. van Genabith (2002): `TTS: A Treebank Tool Suite',
in Proceedings of LREC 2002, Third International Conference on
Language Resources and Evaluation, Las Palmas, Spain, p.1712-1717.
- Frank, A., L. Sadler, J. van Genabith and A. Way (2003): `From
Treebank Resources to LFG f-Structures', in A. Abeille (ed.)
Building and using Parsed Corpora, Kluwer,
Dordrecht, The Netherlands (in press).
- van Genabith, J., L.Sadler, and A.Way. (1999): `Data-driven
Compilation of LFG Semantic Forms', in EACL-99 Workshop on
Linguistically Interpreted Corpora, Bergen, Norway, pp.69-76.
- Zinsemeister, H., J. Kuhn and S. Dipper (2002): `Utilizing LFG Parses
for Treebank Annotation', in M. Butt and T. Holloway-King (eds.)
Proceedings of the Seventh International Conference on LFG, CSLI
Publications, Stanford, CA., pp.427-447.